
How to Collapse Your Stack Using PostgreSQL for Everything
The idea of using PostgreSQL for Everything isn't new, but it's steadily gaining attention, especially as Postgres keeps increasing in popularity. As someone who’s spent most of their career deploying all sorts of databases, here’s what it means to me and how you can apply it to get some simplicity back into your world.
How Technical Sprawl Creeps In
Imagine you're starting on a new product or feature. Early on, your team lists out technical problems you need to tackle. Some solutions you'll develop in-house (your secret sauce), and others you'll address with existing technologies, probably including at least one database.
Unless you're in the business of building databases, it’s usually unwise to develop your own; it's complex, risky, and requires a very specialized skill set. So, you might end up adopting various existing databases: Postgres for transactional data, Elastic for full-text search, Influx for time series, Pinecone for vector operations, and maybe ClickHouse for analytics. Suddenly, your tech stack is sprawling.
Why Stack Sprawl Is a Problem
Each new database you add brings its own set of challenges: different languages to learn, consistency models to understand, and operational nuances that can’t be ignored. Not only does this add complexity, but it also introduces what I call “dotted line” complexity, the additional overhead that comes from each pair of systems which data flows between. The more databases and the more dotted lines you have, the harder it is to reason about the state of your system as a whole.
You’ve got more databases, and because of that, you’ve got more problems.
The Case for Collapsing Your Stack
So what’s the alternative? In my mind, it’s collapsing your stack. If you solve more problems with one database, you’re removing multiple complex pieces of software and the dotted line complexity between them. It’s much easier to keep a mental model of your data flow in your head, as well as reason about the consistency of data at different times. You get time back, which would have been spent on operating these new databases, and you can spend that time building features.
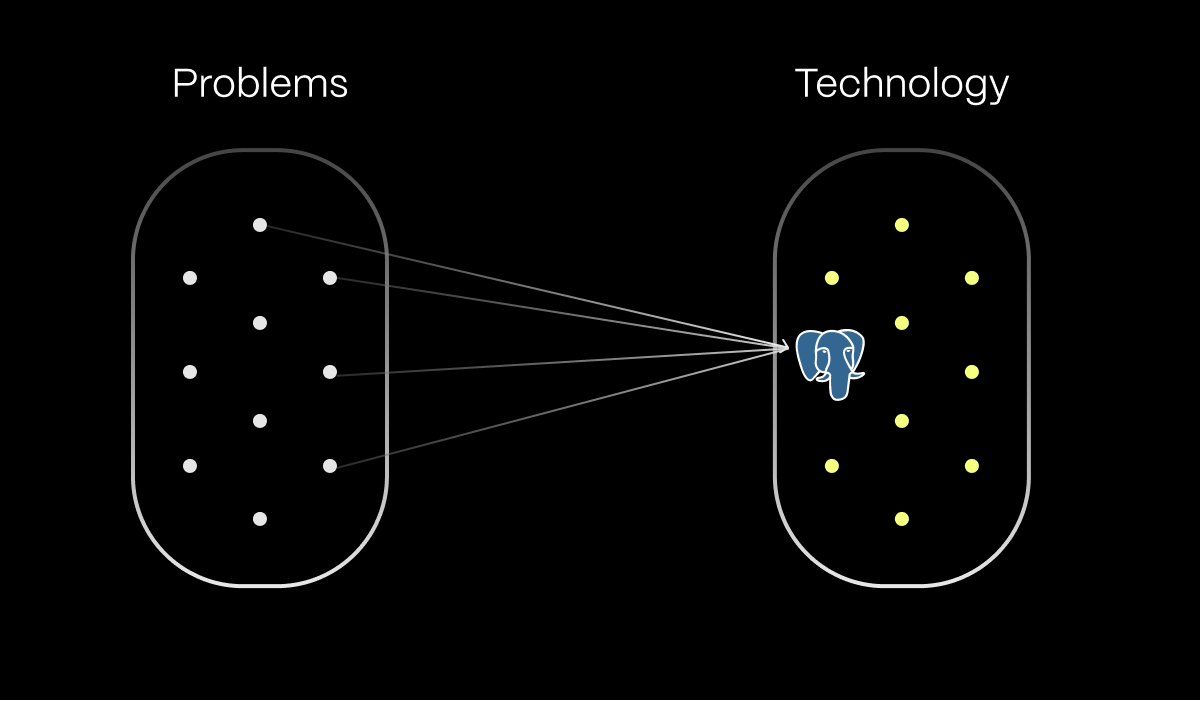
PostgreSQL excels at stack collapsing because it’s simultaneously general-purpose and specialized. As well as being an amazing relational database, it supports a wide range of extra use cases through its advanced extension framework. PostgreSQL can easily handle workloads like full-text search, time-series data, full-text search, and analytics.
PostgreSQL isn’t just versatile, it's also robust and mature. People have been running PostgreSQL in production for over 20 years, and with adoption speeding up, PostgreSQL shows no sign of slowing down. Edge cases are well known, deployment patterns, recovery strategies, and high availability are well defined, and there are many, many companies and champions who can help you along the way.
Because of this, I encourage you to use PostgreSQL to solve as many problems as you can, collapsing your stack, reducing your complexity, and giving you time back to focus on building.
Counterpoint: The Best Tool for the Job?
There’s a well-known argument that you should pick the "best tool for the job," which sometimes gets turned on its head as, “If you’ve only got a hammer, everything looks like a nail.” I don’t see the principle of "PostgreSQL for Everything" contradicting these, as long as you make sure you look at the big picture.
How do you define "The Best Database for the Job"? Is it the fastest? The easiest to use? The most fault-tolerant? Or is it the one that integrates most seamlessly into your existing infrastructure and you know how to use—perhaps one that’s already in place? The best choice usually falls somewhere in between these criteria.

Should you choose database X for its speed, database Y for efficiency, or database Z for its cloud optimization? If good old PostgreSQL does what you need now—with battle-tested effectiveness—and can scale further (perhaps up to 10x your current needs), then I think you should start with the known quantity. Only consider adding other databases when PostgreSQL lacks critical features, weighing the benefits against the added complexity of managing multiple systems. Or, to put it in a slightly different way, Choose Boring Technology (sorry Postgres, I promise I still think you’re exciting).
Let’s consider two possible scenarios:
- PostgreSQL for Everything works: After years, your workload outgrows the original system capabilities. PostgreSQL struggles in some areas, but this is a “good problem”—a sign of success and a cue to evolve your architecture.
- Overengineered with multiple databases: You're set up to handle immense scale, but the system is fragile, full of edge cases, and difficult to maintain. This isn't just challenging; it's a threat to your operation's stability.
Given these scenarios, I’d argue that the theoretical future challenges of a PostgreSQL-centric system are preferable to today’s complexities of opting into a multi-database architecture too early.
A Final Word
"PostgreSQL for Everything" isn't about never using other databases. Honestly, it’s not even about using PostgreSQL for everything. It's a maxim against overengineering your solutions prematurely and an advocate for the benefits of simplicity. Just remember, there are a lot of companies and applications in the world, and with the help of companies like Staas, PostgreSQL will scale to meet most of their demands.
If you want to expand your PostgreSQL database, try Staas. Create a free account today and start simplifying your data stack.
Source: James Blackwood-Sewell
Start building PostgreSQL with Staas.io
PostgreSQL, also known as Postgres, is a free and open-source relational database management system emphasizing extensibility and SQL compliance. It was originally named POSTGRES, referring to its origins as a successor to the Ingres database developed at the University of California, Berkeley.


