AnythingLLM: The easiest way to chat with documents in seconds
It’s becoming clear that the use-case of “chatting with your documents” is becoming the “hello world” of the AI tooling space. It's trivial with tools like LangChain and Pinecone or Chroma, but it is still far from accessible from a user or developer perspective.
CLI (command-line-interface) only tools, downloading and running an entire 10GB+ LLM on your CPU is neither accessible nor realistic for the average consumer device or knowledgebase. That being said projects like localGPT, privateGPT, and GPT4All enable this ecosystem to run totally locally, but not easily.
Support for other well-known vector databases is on the roadmap. Chroma support is now completed as of the writing of this article. Weaviate and others to be done soon!
The Objective
- A tool that takes almost no resources to run on even the lowest-end devices
- Works with off-the-shelf tools like OpenAI’s API and Pinecone DB
- Runs locally with a focus on UI, UX, and cost savings on embeddings of your documents
- Comes complete with tools to automatically convert local documents or remote documents seamlessly
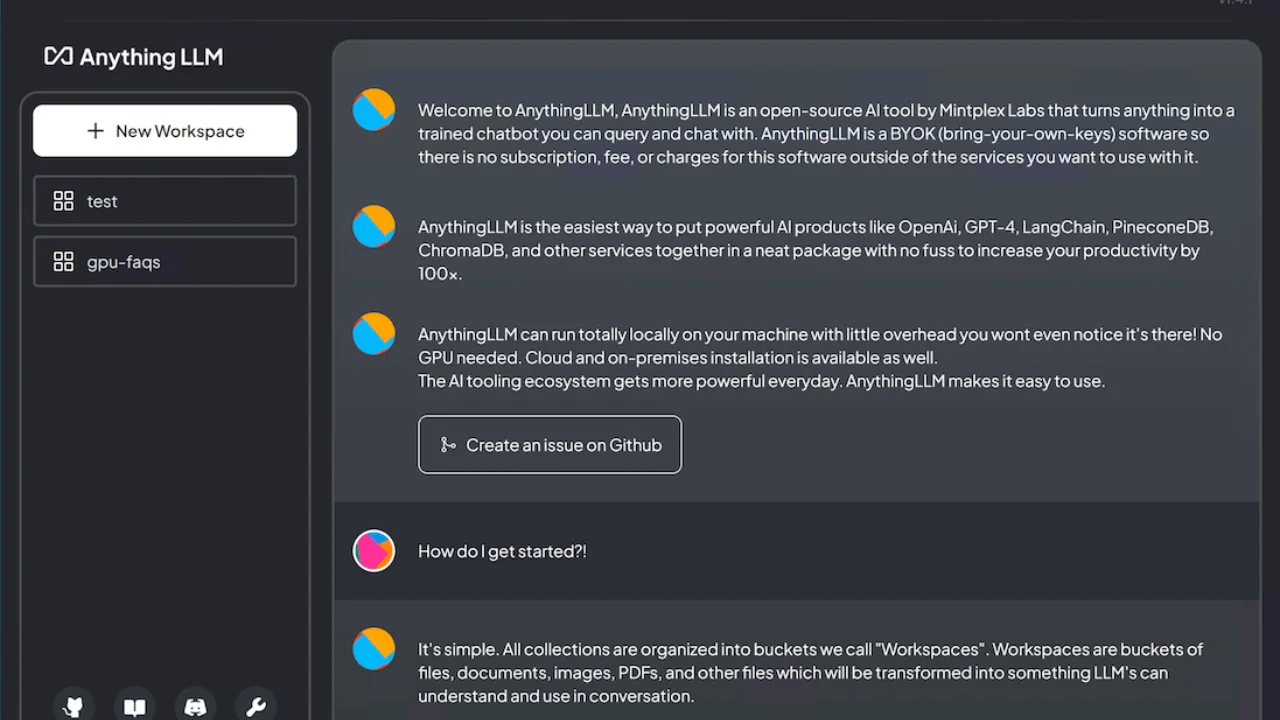
The solution — AnythingLLM
AnythingLLM is an MIT-licensed bring-your-own-keys solution to chatting with your documents in the fastest and most complete package.
Benefits of AnythingLLM over others.
Full Tooling: AnythingLLM comes packaged with two Python scripts that allow you to collect entire YouTube Channels, Substacks, Mediums, Gitbooks, and more as well as auto-magically process local documents you give it.
Runs on anything: AnythingLLM can run passively in the background of your computer and is fully accessible and useable from a web browser with a full UI to manage and chat with your documents.
Full UI and UX: AnythingLLM creates a nice pretty UI that you can interact with to manage, add, and remove documents from your chatbot
Cost-conscious: AnythingLLM utilizes vector caching which basically means if you embed a massive document and pay $1.00 in OpenAI credits, you will never have to pay to embed it again. This simple solution can save you thousands over large document collections.
Logical partitions: AnythingLLM chunks documents into workspaces. Workspaces are like “thought spaces” and have access to documents. Multiple workspaces can share documents but have their own memories built on those documents.
Persistent storage: AnythingLLM can be shut down and once booted back up all your documents, embeddings, and chats will still be available. All stored locally using an SQLite database.
System Requirements:
- Python 3.8+ (for data collection)
- Node16+ (for local server)
- yarn/npm
- OpenAI API key (for embedding + chatting)
- Pinecone DB API Key or locally running ChromaDB instance (for vector storage)
that's it.
Tools for data collection and cleaning
Collect entire YouTube channels, Substacks, and more to be embedded when you want to chat with them.

main.py choices as of v0.0.1-beta
Or you can upload documents collector/hotdir and have them automatically processed.
The AnythingLLM interface
Starting the app is as easy as running two commands. yarn dev:server and yarn dev:frontend. No multi-gigabyte downloads, massive RAM requirements, just two simple JS scripts.
home screen when you first boot up — just a simple demo
The first thing you'll need to do is create a workspace. Just give it a name and you are ready to go!
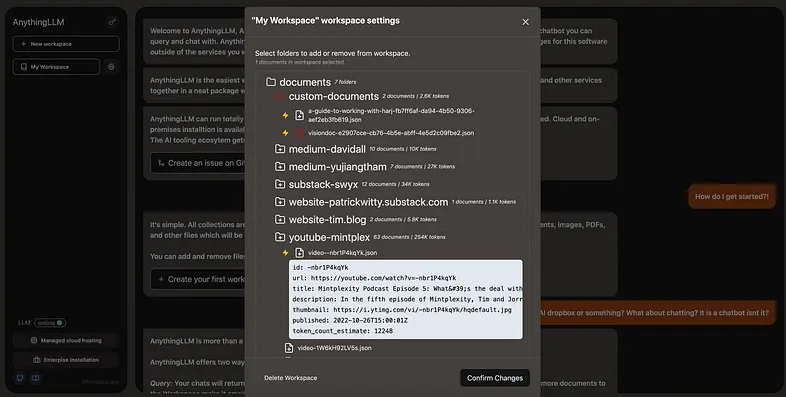
Bring documents into a workspace. This is how you give your chatbot a brain. When you click on the gear icon next to a workspace you will be greeted with all available documents you have collected.
Some cool things to know:
- When you embed a document AnythingLLM will give you a quote for how much it will cost. Keep in mind, with AnythingLLM you will pay this price once because of vector-caching.
- the ⚡ emoji means you have already embedded this document before and the system has a cache for it. Embedding this document will add it to your workspace at no cost! You can of course not use the cached document if you don't want to.
- You can atomically modify workspaces. Add or remove documents from a workspace with ease and without having to re-embed your entire document database. Believe it or not, all other tools lack this feature.
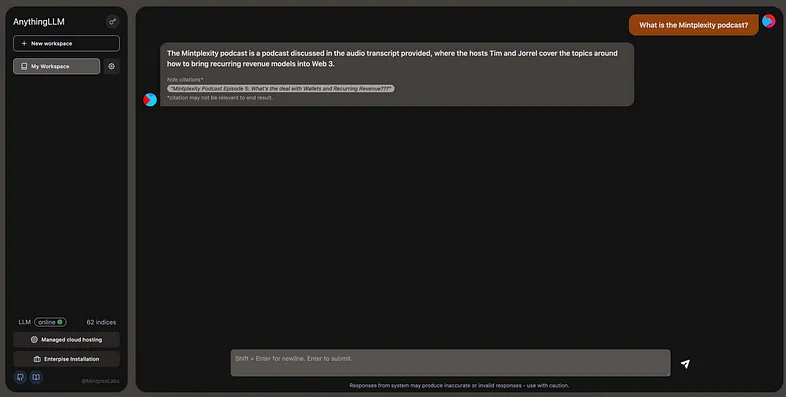
Chatting with your documents or workspace is quite familiar & all responses come with citations. If the citation is a non-local document it will even link to the original source.
Wrapping up
AnythingLLM aims to be the most user-centric open-source document chatbot with incoming integrations with Google Drive, Github repos, and more.
There are ambitions to also allow other vectorDBs like Chroma to be used as well as using other LLMs for chatting or embedding. This application was built in around 1.5 weeks so there is so much more to accomplish.
If chatting with your documents is going to be the hello world of vectorDBs + LLMs then AnythingLLM will be the place it happens.
🔥 At staas.io, we are proud to offer dedicated support and optimization services to help you make the most of AnythingLLM's powerful features.
🌟 You can refer to the documentation on → Launching a AnythingLLM stack in just a few simple steps via Staas.io here

Anything LLM
The all-in-one AI app you were looking for. Chat with your docs, use AI Agents, hyper-configurable, multi-user & no fustrating set up required. A full-stack application that enables you to turn any document, resource, or piece of content into context that any LLM can use as references during chatting. This application allows you to pick and choose which LLM or Vector Database you want to use as well as supporting multi-user management and permissions.
Source: Timothy Carambat