ArangoDB – The Many Faces of a Native Multi-Model Database
ArangoDB is a native multi-model database. Multi-model because ArangoDB provides the capabilities of a graph database, a document database, a key-value store in one C++ core. ArangoDB is native, because users can use and freely combine all supported data models even in a single query. With ArangoDB, users can easily change their data access strategy by just changing a query.
Another huge addition to ArangoDB’s capabilities is the new full-text search and ranking engine – ArangoSearch. ArangoSearch can be used in standalone fashion or be combined with graph traversals, geo queries, aggregations or any other supported access pattern.
ArangoDB as a Document Database
Foundational to the native multi-model in ArangoDB is the flexibility of JSON. Users can store arbitrary complex data and even leverage nested properties in ArangoDB.
All data in ArangoDB is stored as JSON documents and similarly structured documents that can be pooled into collections—similar to a table in relational databases.
{
"_key": "foo",
"_id": "collection/foo",
"text": "...",
"geo_location": [lat, long],
"nested_objects": { ... }
}Document Database Features
ArangoDB can be used as a transactional document store. Data can be queried using AQL, the ArangoDB Query Language.
AQL supports CRUD, aggregations, complex filter conditions, secondary indexes and real JOIN operations
JOIN in AQL
FOR user IN users
FOR friend IN friends
FILTER friend.user==user._key
RETURN {user: user, frien:friend}ArangoDB as a Graph Database
The graph capabilities of ArangoDB are very similar to a property graph database. For each document, a unique _id attribute is stored automatically. To build a relation (i.e., an edge) between two documents (i.e., vertices), both _id attributes are stored in a special edge document known as _from and _to attributes, forming a directed connection between two arbitrary vertices. Edges are then stored in a special edge collection.

ArangoDB enables efficient and scalable graph query performance by using a special hash index on _from and _to attributes (i.e., an edge index).
Vertices and edges are both full JSON documents and can hold arbitrary data. By this approach, ArangoDB is one of the few graph databases capable of horizontal scaling.
Graph Database Features
ArangoDB provides a broad spectrum of graph database features: graph traversals, pattern matching, and path finding algorithms such as shortest path.
Users can also take the result of a JOIN operation, geospatial query, text search or any other access pattern as a starting point for further graph analysis and vice versa – all in one query, if needed. This is an advantage of a native multi-model database like ArangoDB.
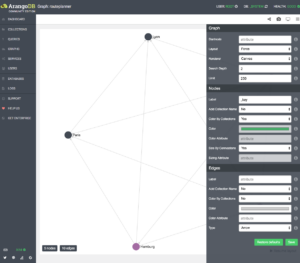
A graph can be visualized and manipulated directly within the ArangoDB WebUI. The WebUI provides many configurations for displaying edges and vertices.
ArangoDB as a Search Engine (ArangoSearch)
ArangoSearch is a natively integrated, C++ based full-text search and similarity ranking engine. Search uses a special type of materialized view to provide full-text search across multiple collections at once. Within the definition of a view type arangosearch, you specify entire collections or individual fields to be covered by an inverted index with one or more general text analyzers. The view concept is currently exclusive to ArangoSearch, more general views (SQL like views, materialized views) may be introduced with later versions of ArangoDB.
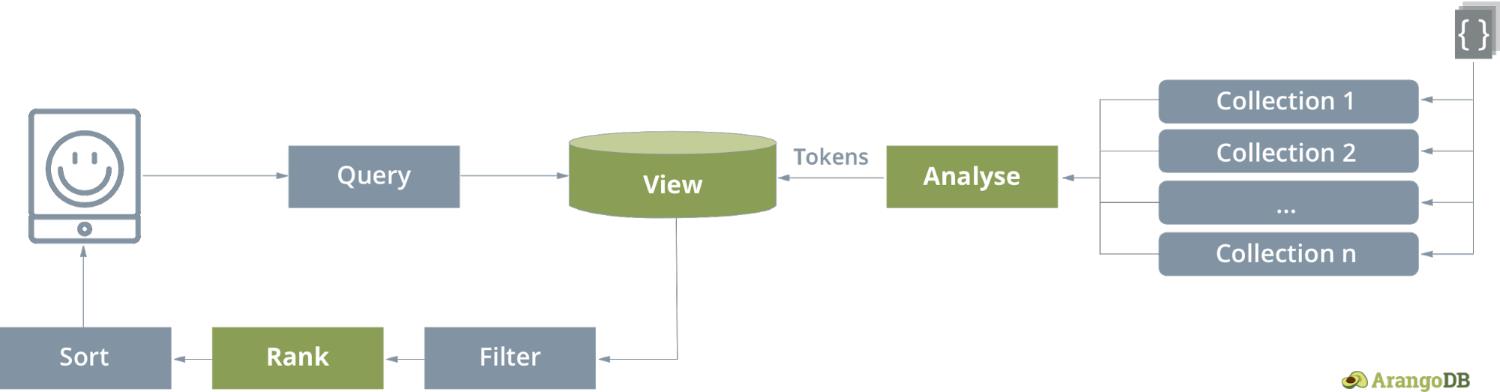
In its current version, results are scored and ranked internally by using the BM25 or TFDIF algorithms. This can be configured by the user.
Search and Ranking Engine Features
With the current version of ArangoSearch, users can already perform a broad spectrum of queries:
- Relevance-based matching;
- Phrase and prefix matching;
- Complex searches with boolean operators; and
- Relevance tuning on runtime.
ArangoSearch also provides language analyzers for twelve common languages including English, Chinese, German, Dutch, Spanish and French. Search queries can be executed against data sharded to an ArangoDB cluster.
ArangoDB as a Key/Value Store
ArangoDB also provides the characteristics of a modern, distributed key/value store. By just storing the document key and a value within a JSON document, some typical key/value operations like CRUD or range queries can be performed efficiently.
To support all the other data models natively, ArangoDB has to store more attributes compared to a “classical” key/value database. Due to this additional overhead, we don’t recommend ArangoDB for key/value use cases which require hyper-scale. A second difference from classical key/value stores is that ArangoDB is not optimized for blob storage (i.e., binary large objects like image files). We recommend to use a dedicated filesystem to store blobs and ArangoDB for storing the metadata.
Native multi-model provides many crucial advantages for modern & agile application development.
Source: ArangoDB