Tokenization – A Complete Guide
Large Language Models (LLMs) have become incredibly popular following the release of OpenAI’s ChatGPT in November 2022. Since then the use of these language models has exploded, helped in part by libraries such as HuggingFace’s Transformer library and PyTorch.
But with all these off-the-shelf tools readily available, it’s easy to abstract away what’s going on at a fundamental level. As such, many online tutorials will give you the what and not the why when creating your own models. That is what this series of articles intends to fix. ‘LLMs from Scratch’ dissects the components that make up large language models, and explains how they work under the hood. The aims in doing so, are:
- To build a fundamental understanding of how LLMs work from first principles, including an intuitive understanding of the mathematics
- To demonstrate how each component works, showing implementations from scratch in Python
- To use as few libraries as possible to reduce any unnecessary abstractions
With that all said, let’s begin.
Part 1 in the “LLMs from Scratch” series — a complete guide to understanding and building Large Language Models. If you are interested in learning more about how these models work I encourage you to read:
- Prelude: A Brief History of Large Language Models
- Part 1: Tokenization — A Complete Guide (Current article)
- Part 2: Word Embeddings with word2vec from Scratch in Python
- Part 3: Self-AttentionExplained with Code
- Part 4: A Complete Guide to BERT with Code
What are Tokenizers?
Natural language problems use textual data, which cannot be immediately understood by a machine. For computers to process language, they first need to convert the text into a numerical form. This process is carried out in two main stages by a model called the tokenizer.
Step 1: Divide the Input Text into Tokens
The tokenizer first takes the text and divides it into smaller pieces, be that words, parts of words, or individual characters. These smaller pieces of text are called tokens. The Stanford NLP Group [2] defines tokens more rigorously as: "An instance of a sequence of characters in some particular document that are grouped together as a useful semantic unit for processing."
Step 2: Assign an ID to Each Token
Once the tokenizer has divided the text into tokens, each token can be assigned an integer number called a token ID. An example of this might be the word cat being assigned the value 15, and so every cat token in the input text is represented by the number 15. The process of replacing the textual tokens with a number representation is called encoding. Similarly, the process of converting encoded tokens back into text is called decoding.
It turns out that using a single number to represent a token has its drawbacks, and so these encodings are processed further to create word embeddings, which are the subject of the next article in this series.
Tokenization Methods
There are three main methods for dividing text into tokens:
- Word-based
- Character-based
- Subword-based
Word-Based Tokenizers:
Word-based tokenization is perhaps the simplest of the three tokenization methods. Here, the tokenizer will divide sentences into words by splitting on each space character (sometimes called ‘whitespace-based tokenization), or by a similar set of rules (such as punctuation-based tokenization, treebank tokenization, etc) [12].
For example, the sentence:
Cats are great, but dogs are better!
Could be split on whitespace characters to give:
['Cats', 'are', 'great,', 'but', 'dogs', 'are', 'better!']
or by split on both punctuation and spaces to give:
['Cats', 'are', 'great', ',', 'but', 'dogs', 'are', 'better', '!']
From this simple example, hopefully it’s clear that the rules used to determine the split are important. The whitespace approach gives the potentially rare token better!, while the second split gives the two, less-rare tokens better and !. Care should be taken not to remove punctuation marks altogether, as they can carry very specific meanings. An example of this is the apostrophe, which can distinguish between the plural and possessive form of words. For example “book’s” refers to some property of a book, as in “the book’s spine is damaged”, and “books” refers to many books, as in “the books are damaged”.
Once the tokens have been generated, each can be assigned a number. The next time a token is generated that the tokenizer has already seen, the token can simply be assigned the number designated for that word. For example, if the token great is assigned the value 1 in the sentence above, all subsequent instances of the word great will also be assigned the value of 1[3].
Pros and Cons of Word-Based Tokenizers:
The tokens produced in word-based methods contain a high degree of information, since each token contains semantic and contextual information. However, one of the largest drawbacks with this method is that very similar words are treated as completely separate tokens. For example, the connection between cat and cats would be non-existent, and so these would be treated as separate words. This becomes a problem in large-scale applications that contain many words, as the possible number of tokens in the model’s vocabulary (the total set of tokens a model has seen) can grow very large. English has around 170,000 words, and so including various grammatical forms like plurals and past-tense for each word can lead to what is known as the exploding vocabulary problem. An example of this is the TransformerXL tokenizer which uses whitespace-based splitting. This led to a vocabulary size of over 250,000 [4].
One way to combat this is by enforcing a hard limit on the number of tokens the model can learn (e.g. 10,000). This would classify any word outside of the 10,000 most frequent tokens as out-of-vocabulary (OOV), and would assign the token value of UNKNOWN instead of a number value (often shortened to UNK). This causes performance to suffer in cases where many unknown words are present, but may be a suitable compromise if the data contains mostly common words. [5]
Summary of Pros:
- Simple method
- High degree of information stored in each token
- Can limit vocabulary size which works well with datasets containing mostly common words
Summary of Cons:
- Separate tokens are created for similar words (e.g. cat and cats)
- Can result in very large vocabulary
- Limiting vocabulary can significantly degrade performance on datasets with many uncommon words
Character-Based Tokenizers:
Character-based tokenization splits text on each character, including: letters, numbers, and special characters such as punctuation. This greatly reduces the vocabulary size, to the point where the English language can be represented with a vocabulary of around 256 tokens, instead of the 170,000+ needed with word-based approaches [5]. Even east Asian languages such as Chinese and Japanese can see a significant reduction in their vocabulary size, despite containing thousands of unique characters in their writing systems.
In a character-based tokenizer, the following sentence:
Cats are great, but dogs are better!
would be converted to:
['C', 'a', 't', 's', ' ', 'a', 'r', 'e', ' ', 'g', 'r', 'e', 'a', 't', ',', ' ', 'b', 'u', 't', ' ', 'd', 'o', 'g', 's', ' ', 'a', 'r', 'e', ' ', 'b', 'e', 't', 't', 'e', 'r', '!']
Pros and Cons of Character-Based Tokenizers:
Character-based approaches result in a much smaller vocabulary size when compared to word-based methods, and also result in much fewer out-of-vocabulary tokens. This even allows misspelled words to be tokenized (albeit differently than the correct form of the word), rather than being removed immediately due to the frequency-based vocabulary limit.
However there are a number of drawbacks with this approach too. Firstly, the information stored in a single token produced with a character-based method is very low. This is because unlike the tokens in the word-based method, no semantic or contextual meaning is captured (especially in languages with alphabet-based writing systems like English). Finally, the size of the tokenized input that can be fed into a language model is limited with this approach, since many numbers are required to encode the input text.
Summary of Pros:
- Smaller vocabulary size
- Does not remove misspelled words
Summary of Cons:
- Low information stored in each token, little-to-no contextual or semantic meaning (especially with alphabet-based writing systems)
- Size of input to language models is limited since the output of the tokenizer requires many more numbers to tokenize text (when compared to a word-based approach)
Subword-Based Tokenizers:
Subword-based tokenization aims to achieve the benefits of both word-based and character-based methods, while minimising their downsides. Subword-based methods take a middle ground by splitting text within words in an attempt to create tokens with semantic meaning, even if they are not full words. For example, the tokens ing and ed carry grammatical meaning, although they are not words in themselves.
This method results in a vocabulary size that is smaller than those found in word-based methods, but larger than those found in character-based methods. The same is also true for the amount of information stored within each token, which is also in between the tokens generated by the previous two methods. The subword approach uses the following two guidelines:
- Frequently-used words should not be split into subwords, but rather be stored as entire tokens
- Infrequently used words should be split into subwords
Splitting only the infrequently used words gives a chance for the conjugations, plural forms etc to be decomposed into their constituent parts, while preserving the relationship between tokens. For example cat might be a very common word in the dataset, but cats might be less common. For this reason, cats would be split into cat and s, where cat is now assigned the same value as every other cat token, and s is assigned a different value, which can encode the meaning of plurality. Another example would be the word tokenization, which can be split into the root word token and the suffix ization. This method can therefore preserve syntactic and semantic similarity [6]. For these reasons, subword-based tokenizers are very commonly used in NLP models today.
Normalization and Pre-Tokenization
The tokenization process requires some pre-processing and post-processing steps, that in all comprise the tokenization pipeline. This describes the entires series of actions that are taken to convert raw text into tokens. The steps of this pipeline are:
- Normalization
- Pre-tokenization
- Model
- Post-processing
where the tokenization method (be that subword-based, character-based etc) takes place in the model step [7]. This section will cover each of these steps for a tokenizer that uses a subword-based tokenization approach.
IMPORTANT NOTE: all the steps of the tokenization pipeline are handled for the user automatically when using a tokenizer from libraries such as the Hugging Face tokenizers and transformers libraries. The entire pipeline is performed by a single object called the Tokenizer. This section dives into the inner workings of the code the most users do not need to handle manually when working with NLP tasks. Later, the steps to customise the base tokenizer class in the tokenizers library is also presented, so that a tokenizer can be purpose-built for a specific task if required.
Normalization Methods
Normalization is the process of cleaning text before it is split into tokens. This includes steps such as converting each character to lowercase, removing accents from characters (e.g. é becomes e), removing unnecessary whitespace, and so on. For example, the string ThÍs is áN ExaMPlé sÉnteNCE becomes this is an example sentence after normalization. Different normalizers will perform different steps, which can be useful depending on the use-case. For example, in some situations the casing or accents might need to be preserved. Depending on the normalizer chosen, different effects can be achieved at this stage.
The Hugging Face tokenizers.normalizers package contains several basic normalizers that are used by different tokenizers as part of larger models. Below shows the NFC unicode, Lowercase, and BERT normalizers. These show the following effects on the example sentence:
- NFC: Does not convert casing or remove accents
- Lower: Converts casing but does not remove accents
- BERT: Converts casing and removes accents
from tokenizers.normalizers import NFC, Lowercase, BertNormalizer
# Text to normalize
text = 'ThÍs is áN ExaMPlé sÉnteNCE'
# Instantiate normalizer objects
NFCNorm = NFC()
LowercaseNorm = Lowercase()
BertNorm = BertNormalizer()
# Normalize the text
print(f'NFC: {NFCNorm.normalize_str(text)}')
print(f'Lower: {LowercaseNorm.normalize_str(text)}')
print(f'BERT: {BertNorm.normalize_str(text)}')NFC: ThÍs is áN ExaMPlé sÉnteNCE
Lower: thís is án examplé séntence
BERT: this is an example sentenceThe normalizers above are used in tokenizer models which can be imported from the Hugging Face transformers library. The code cell below shows how the normalizers can be accessed using dot notation via Tokenizer.backend_tokenizer.normalizer. Some comparisons are shown between the tokenizers to highlight the different normalization methods that are used. Note that in these examples, only the FNet normalizer removes unncessary whitespace.
from transformers import FNetTokenizerFast, CamembertTokenizerFast, \
BertTokenizerFast
# Text to normalize
text = 'ThÍs is áN ExaMPlé sÉnteNCE'
# Instantiate tokenizers
FNetTokenizer = FNetTokenizerFast.from_pretrained('google/fnet-base')
CamembertTokenizer = CamembertTokenizerFast.from_pretrained('camembert-base')
BertTokenizer = BertTokenizerFast.from_pretrained('bert-base-uncased')
# Normalize the text
print(f'FNet Output: \
{FNetTokenizer.backend_tokenizer.normalizer .normalize_str(text)}')
print(f'CamemBERT Output: \
{CamembertTokenizer.backend_tokenizer.normalizer.normalize_str(text)}')
print(f'BERT Output: \
{BertTokenizer.backend_tokenizer.normalizer.normalize_str(text)}')FNet Output: ThÍs is áN ExaMPlé sÉnteNCE
CamemBERT Output: ThÍs is áN ExaMPlé sÉnteNCE
BERT Output: this is an example sentencePre-Tokenization Methods
The pre-tokenization step is the first splitting of the raw text in the tokenization pipeline. The split is performed to give an upper bound to what the final tokens could be at the end of the pipeline. That is, a sentence can be split into words in the pre-tokenization step, then in the model step some of these words may be split further according to the tokenization method (e.g. subword-based). So the pre-tokenized text represents the largest possible tokens that could still remain after tokenization.
Just like with normalization, there are several ways that this step can be performed. For example, a sentence can be split based on every space, every space and some punctuation, or every space and every punctuation.
The cell below shows a comparison between the basic Whitespacesplit pre-tokenizer, and slightly more complex BertPreTokenizer from the Hugging Face tokenizers.pre_tokenizers package. The output of the whitespace pre-tokenizer leaves the punctuation intact, and still attached to the neighbouring words. For example includes: is treated as a single word in this case. Whereas the BERT pre-tokenizer treats punctuation as individual words [8].
from tokenizers.pre_tokenizers import WhitespaceSplit, BertPreTokenizer
# Text to normalize
text = ("this sentence's content includes: characters, spaces, and " \
"punctuation.")
# Define helper function to display pre-tokenized output
def print_pretokenized_str(pre_tokens):
for pre_token in pre_tokens:
print(f'"{pre_token[0]}", ', end='')
# Instantiate pre-tokenizers
wss = WhitespaceSplit()
bpt = BertPreTokenizer()
# Pre-tokenize the text
print('Whitespace Pre-Tokenizer:')
print_pretokenized_str(wss.pre_tokenize_str(text))
print('\n\nBERT Pre-Tokenizer:')
print_pretokenized_str(bpt.pre_tokenize_str(text))Whitespace Pre-Tokenizer:
"this", "sentence's", "content", "includes:", "characters,", "spaces,",
"and", "punctuation.",
BERT Pre-Tokenizer:
"this", "sentence", "'", "s", "content", "includes", ":", "characters",
",", "spaces", ",", "and", "punctuation", ".", Just as with the normalization methods, you can call the pre-tokenization methods directly from common tokenizers such as the GPT-2 and ALBERT (A Lite BERT) tokenizers. These take a slightly different approach to the standard BERT pre-tokenizer shown above, in that space characters are not removed when splitting the tokens. Instead, they are replaced with special characters that represent where the space was. This has the advantage in that the space characters can be ignored when processing further, but the original sentence can be retrieved if required. The GPT-2 model uses the Ġ character, which features a capital G with a dot above. The ALBERT model uses an underscore character.
from transformers import AutoTokenizer
# Text to pre-tokenize
text = ("this sentence's content includes: characters, spaces, and " \
"punctuation.")
# Instatiate the pre-tokenizers
GPT2_PreTokenizer = AutoTokenizer.from_pretrained('gpt2').backend_tokenizer \
.pre_tokenizer
Albert_PreTokenizer = AutoTokenizer.from_pretrained('albert-base-v1') \
.backend_tokenizer.pre_tokenizer
# Pre-tokenize the text
print('GPT-2 Pre-Tokenizer:')
print_pretokenized_str(GPT2_PreTokenizer.pre_tokenize_str(text))
print('\n\nALBERT Pre-Tokenizer:')
print_pretokenized_str(Albert_PreTokenizer.pre_tokenize_str(text))GPT-2 Pre-Tokenizer:
"this", "Ġsentence", "'s", "Ġcontent", "Ġincludes", ":", "Ġcharacters", ",",
"Ġspaces", ",", "Ġand", "Ġpunctuation", ".",
ALBERT Pre-Tokenizer:
"▁this", "▁sentence's", "▁content", "▁includes:", "▁characters,", "▁spaces,",
"▁and", "▁punctuation.",Below shows the results of a BERT pre-tokenization step on the same example sentence without any of the modifications to the outputs as was shown above. The object returned is a Python list containing tuples. Each tuple corresponds to a pre-token, where the first element is the pre-token string, and the second element is a tuple containing the index for the start and end of the string in the original input text. Note that the starting index of the string is inclusive, and the ending index is exclusive.
from tokenizers.pre_tokenizers import WhitespaceSplit, BertPreTokenizer
# Text to pre-tokenize
text = ("this sentence's content includes: characters, spaces, and " \
"punctuation.")
# Instantiate pre-tokenizer
bpt = BertPreTokenizer()
# Pre-tokenize the text
bpt.pre_tokenize_str(text)[('this', (0, 4)),
('sentence', (5, 13)),
("'", (13, 14)),
('s', (14, 15)),
('content', (16, 23)),
('includes', (24, 32)),
(':', (32, 33)),
('characters', (34, 44)),
(',', (44, 45)),
('spaces', (46, 52)),
(',', (52, 53)),
('and', (54, 57)),
('punctuation', (58, 69)),
('.', (69, 70))]Subword Tokenization Methods
The model step of the tokenization pipeline is where the tokenization method comes into play. As described earlier, the options here are: word-based, character-based, and subword-based. Subword-based are generally favoured, since these methods were designed to overcome the limitations of the word-based and character-based approaches.
For transformer models, there are three tokenizer methods that are commonly used to implement subword-based tokenization. These include:
- Byte Pair Encoding (BPE)
- WordPiece
- Unigram
Each of these use slightly different techniques to split the less frequent words into smaller tokens, which are laid out in this section. In addition, implementations of the BPE and WordPiece algorithms are also shown to help highlight some of the similarities and differences between the approaches.
Byte Pair Encoding
The Byte Pair Encoding algorithm is a commonly-used tokenizer that is found in many transformer models such as GPT and GPT-2 models (OpenAI), BART (Lewis et al.), and many others [9–10]. It was originally designed as a text compression algorithm, but has been found to work very well in tokenization tasks for language models. The BPE algorithm decomposes a string of text into subword units that appear frequently in a reference corpus (the text used to train the tokenization model) [11]. The BPE model is trained as follows:
Step 1) Construct the Corpus
The input text is given to the normalization and pre-tokenization models to create clean words. The words are then given to the BPE model, which determines the frequency of each word, and stores this number alongside the word in a list called the corpus.
Step 2) Construct the Vocabulary
The words from the corpus are then broken down individual characters and are added to an empty list called the vocabulary. The algorithm will iteratively add to this vocabulary every time it determines which character pairs can be merged together.
Step 3) Find the Frequency of Character Pairs
The frequency of character pairs is then recorded for each word in the corpus. For example, the words cats will have the character pairs ca, at, and ts. All the words are examined in this way, and contribute to a global frequency counter. So any instance of ca found in any of the tokens will increase the frequency counter for the ca pair.
Step 4) Create a Merging Rule
When the frequency for each character pair is known, the most frequent character pair is added to the vocabulary. The vocabulary now consists of every individual letter in the tokens, plus the most frequent character pair. This also gives a merging rule that the model can use. For example, if the model learns that ca is the most frequent character pair, it has learned that all adjacent instances of c and a in the corpus can be merged to give ca. This can now be treated as a single character ca for the remainder of the steps.
Step 5) Repeat Steps 3 and 4
Steps 3 and are then repeated, finding more merging rules, and adding more character pairs to the vocabulary. This process continues until the vocabulary size reaches a target size specified at the beginning of the training.
Now that the BPE algorithm has been trained (i.e. now that all have the merging rules have been found), the model can be used to tokenize any text by first splitting each of the words on every character, and then merging according to the merge rules.
Below is a Python implementation of the BPE algorithm, following the steps outlined above. Afterwards, the model is then trained on a toy dataset and tested on some example words.
class TargetVocabularySizeError(Exception):
def __init__(self, message):
super().__init__(message)
class BPE:
'''An implementation of the Byte Pair Encoding tokenizer.'''
def calculate_frequency(self, words):
''' Calculate the frequency for each word in a list of words.
Take in a list of words stored as strings and return a list of
tuples where each tuple contains a string from the words list,
and an integer representing its frequency count in the list.
Args:
words (list): A list of words (strings) in any order.
Returns:
corpus (list[tuple(str, int)]): A list of tuples where the
first element is a string of a word in the words list, and
the second element is an integer representing the frequency
of the word in the list.
'''
freq_dict = dict()
for word in words:
if word not in freq_dict:
freq_dict[word] = 1
else:
freq_dict[word] += 1
corpus = [(word, freq_dict[word]) for word in freq_dict.keys()]
return corpus
def create_merge_rule(self, corpus):
''' Create a merge rule and add it to the self.merge_rules list.
Args:
corpus (list[tuple(list, int)]): A list of tuples where the
first element is a list of a word in the words list (where
the elements are the individual characters (or subwords in
later iterations) of the word), and the second element is
an integer representing the frequency of the word in the
list.
Returns:
None
'''
pair_frequencies = self.find_pair_frequencies(corpus)
most_frequent_pair = max(pair_frequencies, key=pair_frequencies.get)
self.merge_rules.append(most_frequent_pair.split(','))
self.vocabulary.append(most_frequent_pair)
def create_vocabulary(self, words):
''' Create a list of every unique character in a list of words.
Args:
words (list): A list of strings containing the words of the
input text.
Returns:
vocabulary (list): A list of every unique character in the list
of input words.
'''
vocabulary = list(set(''.join(words)))
return vocabulary
def find_pair_frequencies(self, corpus):
''' Find the frequency of each character pair in the corpus.
Loop through the corpus and calculate the frequency of each pair
of adjacent characters across every word. Return a dictionary of
each character pair as the keys and the corresponding frequency as
the values.
Args:
corpus (list[tuple(list, int)]): A list of tuples where the
first element is a list of a word in the words list (where
the elements are the individual characters (or subwords in
later iterations) of the word), and the second element is
an integer representing the frequency of the word in the
list.
Returns:
pair_freq_dict (dict): A dictionary where the keys are the
character pairs from the input corpus and the values are an
integer representing the frequency of the pair in the
corpus.
'''
pair_freq_dict = dict()
for word, word_freq in corpus:
for idx in range(len(word)-1):
char_pair = f'{word[idx]},{word[idx+1]}'
if char_pair not in pair_freq_dict:
pair_freq_dict[char_pair] = word_freq
else:
pair_freq_dict[char_pair] += word_freq
return pair_freq_dict
def get_merged_chars(self, char_1, char_2):
''' Merge the highest score pair and return to the self.merge method.
This method is abstracted so that the BPE class can be used as the
base class for other Tokenizers, and so the merging method can be
easily overwritten. For example, in the BPE algorithm the
characters can simply be concatenated and returned. However in the
WordPiece algorithm, the # symbols must first be stripped.
Args:
char_1 (str): The first character in the highest-scoring pair.
char_2 (str): The second character in the highest-scoring pair.
Returns:
merged_chars (str): Merged characters.
'''
merged_chars = char_1 + char_2
return merged_chars
def initialize_corpus(self, words):
''' Split each word into characters and count the word frequency.
Split each word in the input word list on every character. For each
word, store the split word in a list as the first element inside a
tuple. Store the frequency count of the word as an integer as the
second element of the tuple. Create a tuple for every word in this
fashion and store the tuples in a list called 'corpus', then return
then corpus list.
Args:
None
Returns:
corpus (list[tuple(list, int)]): A list of tuples where the
first element is a list of a word in the words list (where
the elements are the individual characters of the word),
and the second element is an integer representing the
frequency of the word in the list.
'''
corpus = self.calculate_frequency(words)
corpus = [([*word], freq) for (word, freq) in corpus]
return corpus
def merge(self, corpus):
''' Loop through the corpus and perform the latest merge rule.
Args:
corpus (list[tuple(list, int)]): A list of tuples where the
first element is a list of a word in the words list (where
the elements are the individual characters (or subwords in
later iterations) of the word), and the second element is
an integer representing the frequency of the word in the
list.
Returns:
new_corpus (list[tuple(list, int)]): A modified version of the
input argument where the most recent merge rule has been
applied to merge the most frequent adjacent characters.
'''
merge_rule = self.merge_rules[-1]
new_corpus = []
for word, word_freq in corpus:
new_word = []
idx = 0
while idx < len(word):
# If a merge pattern has been found
if (len(word) != 1) and (word[idx] == merge_rule[0]) and\
(word[idx+1] == merge_rule[1]):
new_word.append(self.get_merged_chars(word[idx],word[idx+1]))
idx += 2
# If a merge patten has not been found
else:
new_word.append(word[idx])
idx += 1
new_corpus.append((new_word, word_freq))
return new_corpus
def train(self, words, target_vocab_size):
''' Train the model.
Args:
words (list[str]): A list of words to train the model on.
target_vocab_size (int): The number of words in the vocabulary
to be used as the stopping condition when training.
Returns:
None.
'''
self.words = words
self.target_vocab_size = target_vocab_size
self.corpus = self.initialize_corpus(self.words)
self.corpus_history = [self.corpus]
self.vocabulary = self.create_vocabulary(self.words)
self.vocabulary_size = len(self.vocabulary)
self.merge_rules = []
# Iteratively add vocabulary until reaching the target vocabulary size
if len(self.vocabulary) > self.target_vocab_size:
raise TargetVocabularySizeError(f'Error: Target vocabulary size \
must be greater than the initial vocabulary size \
({len(self.vocabulary)})')
else:
while len(self.vocabulary) < self.target_vocab_size:
try:
self.create_merge_rule(self.corpus)
self.corpus = self.merge(self.corpus)
self.corpus_history.append(self.corpus)
# If no further merging is possible
except ValueError:
print('Exiting: No further merging is possible')
break
def tokenize(self, text):
''' Take in some text and return a list of tokens for that text.
Args:
text (str): The text to be tokenized.
Returns:
tokens (list): The list of tokens created from the input text.
'''
tokens = [*text]
for merge_rule in self.merge_rules:
new_tokens = []
idx = 0
while idx < len(tokens):
# If a merge pattern has been found
if (len(tokens) != 1) and (tokens[idx] == merge_rule[0]) and \
(tokens[idx+1] == merge_rule[1]):
new_tokens.append(self.get_merged_chars(tokens[idx],
tokens[idx+1]))
idx += 2
# If a merge patten has not been found
else:
new_tokens.append(tokens[idx])
idx += 1
tokens = new_tokens
return tokensThe BPE algorithm is trained below on a toy dataset that contains some words about cats. The goal of the tokenizer is to determine the most useful, meaningful subunits of the words in the dataset to be used as tokens. From inspection, it is clear that units such as cat, eat and ing would be useful subunits.
Running the tokenizer with a target vocabulary size of 21 (which only requires 5 merges) is enough for the tokenizer to capture all the desired subunits mentioned above. With a larger dataset, the target vocabulary would be much higher, but this shows how powerful the BPE tokenizer can be.
# Training set
words = ['cat', 'cat', 'cat', 'cat', 'cat',
'cats', 'cats',
'eat', 'eat', 'eat', 'eat', 'eat', 'eat', 'eat', 'eat', 'eat', 'eat',
'eating', 'eating', 'eating',
'running', 'running',
'jumping',
'food', 'food', 'food', 'food', 'food', 'food']
# Instantiate the tokenizer
bpe = BPE()
bpe.train(words, 21)
# Print the corpus at each stage of the process, and the merge rule used
print(f'INITIAL CORPUS:\n{bpe.corpus_history[0]}\n')
for rule, corpus in list(zip(bpe.merge_rules, bpe.corpus_history[1:])):
print(f'NEW MERGE RULE: Combine "{rule[0]}" and "{rule[1]}"')
print(corpus, end='\n\n')INITIAL CORPUS:
[(['c', 'a', 't'], 5), (['c', 'a', 't', 's'], 2), (['e', 'a', 't'], 10),
(['e', 'a', 't', 'i', 'n', 'g'], 3), (['r', 'u', 'n', 'n', 'i', 'n', 'g'], 2),
(['j', 'u', 'm', 'p', 'i', 'n', 'g'], 1), (['f', 'o', 'o', 'd'], 6)]
NEW MERGE RULE: Combine "a" and "t"
[(['c', 'at'], 5), (['c', 'at', 's'], 2), (['e', 'at'], 10),
(['e', 'at', 'i', 'n', 'g'], 3), (['r', 'u', 'n', 'n', 'i', 'n', 'g'], 2),
(['j', 'u', 'm', 'p', 'i', 'n', 'g'], 1), (['f', 'o', 'o', 'd'], 6)]
NEW MERGE RULE: Combine "e" and "at"
[(['c', 'at'], 5), (['c', 'at', 's'], 2), (['eat'], 10),
(['eat', 'i', 'n', 'g'], 3), (['r', 'u', 'n', 'n', 'i', 'n', 'g'], 2),
(['j', 'u', 'm', 'p', 'i', 'n', 'g'], 1), (['f', 'o', 'o', 'd'], 6)]
NEW MERGE RULE: Combine "c" and "at"
[(['cat'], 5), (['cat', 's'], 2), (['eat'], 10), (['eat', 'i', 'n', 'g'], 3),
(['r', 'u', 'n', 'n', 'i', 'n', 'g'], 2),
(['j', 'u', 'm', 'p', 'i', 'n', 'g'], 1), (['f', 'o', 'o', 'd'], 6)]
NEW MERGE RULE: Combine "i" and "n"
[(['cat'], 5), (['cat', 's'], 2), (['eat'], 10), (['eat', 'in', 'g'], 3),
(['r', 'u', 'n', 'n', 'in', 'g'], 2), (['j', 'u', 'm', 'p', 'in', 'g'], 1),
(['f', 'o', 'o', 'd'], 6)]
NEW MERGE RULE: Combine "in" and "g"
[(['cat'], 5), (['cat', 's'], 2), (['eat'], 10), (['eat', 'ing'], 3),
(['r', 'u', 'n', 'n', 'ing'], 2), (['j', 'u', 'm', 'p', 'ing'], 1),
(['f', 'o', 'o', 'd'], 6)]Now that the BPE algorithm has been trained with this very small dataset, it can be used to tokenize some example words. The cell below shows the tokenizer being used to tokenize some words it has seen before, and some it has not. Notice that the tokenizer has learned the verb ending ing, and so can split these characters into a token, even in words it has never seen before. In the case of eating, the training data contained the word eat, and so the model was able to learn that this is a significant token all by itself. However, the model has never seen the words run and ski, and so does not successfully tokenize these as root words. This highlights the important of a wide and varied training set when training a tokenizer.
print(bpe.tokenize('eating'))
print(bpe.tokenize('running'))
print(bpe.tokenize('skiing'))['eat', 'ing']
['r', 'u', 'n', 'n', 'ing']
['s', 'k', 'i', 'ing']BPE tokenizers can only recognise characters that have appeared in the training data. For example, the training data above only contained the characters needed to talk about cats, which happened to not require a z. Therefore, that version of the tokenizer does not contain the character z in its vocabulary and so would convert that character to an unknown token if the model was used to tokenize real data (actually, error handling was not added to instruct the model to create unknown tokens and so it would crash, but for productionized models this is the case).
The BPE tokenizers used in GPT-2 and RoBERTa do not have this issue due to a trick within the code. Instead of analysing the training data based on the Unicode characters, they instead analyse the character’s bytes. This is called Byte-Level BPE and allows a small base vocabulary to be able to tokenize all characters the model might see.
WordPiece
WordPiece is a tokenization method developed by Google for their seminal BERT model, and is used in its derivative models such as DistilBERT and MobileBERT.
The full details of the WordPiece algorithm have not been fully released to the public, and so the methodology presented here is based on an interpretation given by Hugging Face [12]. The WordPiece algorithm is similar to BPE, but uses a different metric to determine the merge rules. Instead of choosing the most frequent character pair, a score is calculated for each pair instead, and the pair with the highest score determines which characters are merged. WordPiece is trained as follows:
Step 1) Construct the Corpus
Again, the input text is given to the normalization and pre-tokenization models to create clean words. The words are then given to the WordPiece model, which determines the frequency of each word, and stores this number alongside the word in a list called the corpus.
Step 2) Construct the Vocabulary
As with BPE, the words from the corpus are then broken down individual characters and are added to an empty list called the vocabulary. However this time, instead of storing simply each individual character, two # symbols are used as markers to determine whether the character was found at the beginning of a word, or from the middle/end of a word. For example, the word cat would be split into ['c', 'a', 't'] in BPE, but in WordPiece it would look like ['c', '##a', '##t']. In this system, c at the beginning of a word, and ##c from the middle or end of a word, would be treated differently. As before, he algorithm will iteratively add to this vocabulary every time it determines which character pairs can be merged together.
Step 3) Calculate the Pair Score for Each Adjacent Character Pair
Unlike the BPE model, this time a score is calculated for each of the character pairs. First, each adjacent character pair in the corpus is identified, e.g. 'c##a', ##a##t and so on, and the frequency is counted. The frequency of each character individually is also determined. With these values known, a pair score can then be calculated according to the following formula:
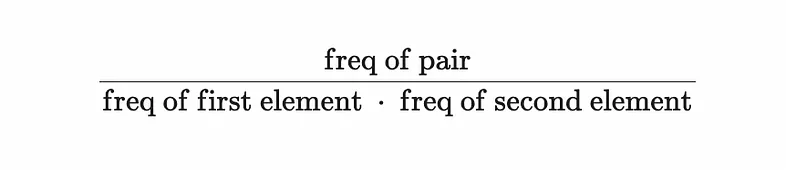
WordPiece pair score equation
This metric assigns higher scores to characters that appear frequently together, but less frequently on their own or with other characters. This is the main difference between WordPiece and BPE, since BPE does not take into account the overall frequency of the individual characters on their own.
Step 4) Create a Merging Rule
High scores represent character pairs that are commonly seen together. That is, if c##a has a high pair score, then c and a are frequently seen together in the corpus, and not so frequently seen separately. Just as with BPE, the merging rule is determined by taking the character pair with the highest score, but this time instead of frequency determining the score, it’s the pair score.
Step 5) Repeat Steps 3 and 4
Steps 3 and 4 are then repeated, finding more merging rules, and adding more character pairs to the vocabulary. This process continues until the vocabulary size reaches a target size specified at the beginning of the training.
Below is an implementation of WordPiece which inherits from the BPE model written earlier.
class WordPiece(BPE):
def add_hashes(self, word):
''' Add # symbols to every character in a word except the first.
Take in a word as a string and add # symbols to every character
except the first. Return the result as a list where each element is
a character with # symbols in front, except the first character
which is just the plain character.
Args:
word (str): The word to add # symbols to.
Returns:
hashed_word (list): A list of the characters with # symbols
(except the first character which is just the plain
character).
'''
hashed_word = [word[0]]
for char in word[1:]:
hashed_word.append(f'##{char}')
return hashed_word
def create_merge_rule(self, corpus):
''' Create a merge rule and add it to the self.merge_rules list.
Args:
corpus (list[tuple(list, int)]): A list of tuples where the
first element is a list of a word in the words list (where
the elements are the individual characters (or subwords in
later iterations) of the word), and the second element is
an integer representing the frequency of the word in the
list.
Returns:
None
'''
pair_frequencies = self.find_pair_frequencies(corpus)
char_frequencies = self.find_char_frequencies(corpus)
pair_scores = self.find_pair_scores(pair_frequencies, char_frequencies)
highest_scoring_pair = max(pair_scores, key=pair_scores.get)
self.merge_rules.append(highest_scoring_pair.split(','))
self.vocabulary.append(highest_scoring_pair)
def create_vocabulary(self, words):
''' Create a list of every unique character in a list of words.
Unlike the BPE algorithm where each character is stored normally,
here a distinction is made by characters that begin a word
(unmarked), and characters that are in the middle or end of a word
(marked with a '##'). For example, the word 'cat' will be split
into ['c', '##a', '##t'].
Args:
words (list): A list of strings containing the words of the
input text.
Returns:
vocabulary (list): A list of every unique character in the list
of input words, marked accordingly with ## to denote if the
character was featured in the middle/end of a word, instead
of as the first character of the word.
'''
vocabulary = set()
for word in words:
vocabulary.add(word[0])
for char in word[1:]:
vocabulary.add(f'##{char}')
# Convert to list so the vocabulary can be appended to later
vocabulary = list(vocabulary)
return vocabulary
def find_char_frequencies(self, corpus):
''' Find the frequency of each character in the corpus.
Loop through the corpus and calculate the frequency of characters.
Note that 'c' and '##c' are different characters, since the first
represents a 'c' at the start of a word, and '##c' represents a 'c'
in the middle/end of a word. Return a dictionary of each character
pair as the keys and the corresponding frequency as the values.
Args:
corpus (list[tuple(list, int)]): A list of tuples where the
first element is a list of a word in the words list (where
the elements are the individual characters (or subwords in
later iterations) of the word), and the second element is
an integer representing the frequency of the word in the
list.
Returns:
pair_freq_dict (dict): A dictionary where the keys are the
characters from the input corpus and the values are an
integer representing the frequency.
'''
char_frequencies = dict()
for word, word_freq in corpus:
for char in word:
if char in char_frequencies:
char_frequencies[char] += word_freq
else:
char_frequencies[char] = word_freq
return char_frequencies
def find_pair_scores(self, pair_frequencies, char_frequencies):
''' Find the pair score for each character pair in the corpus.
Loops through the pair_frequencies dictionary and calculate the
pair score for each pair of adjacent characters in the corpus.
Store the scores in a dictionary and return it.
Args:
pair_frequencies (dict): A dictionary where the keys are the
adjacent character pairs in the corpus and the values are
the frequencies of each pair.
char_frequencies (dict): A dictionary where the keys are the
characters in the corpus and the values are corresponding
frequencies.
Returns:
pair_scores (dict): A dictionary where the keys are the
adjacent character pairs in the input corpus and the values
are the corresponding pair score.
'''
pair_scores = dict()
for pair in pair_frequencies.keys():
char_1 = pair.split(',')[0]
char_2 = pair.split(',')[1]
denominator = (char_frequencies[char_1]*char_frequencies[char_2])
score = (pair_frequencies[pair]) / denominator
pair_scores[pair] = score
return pair_scores
def get_merged_chars(self, char_1, char_2):
''' Merge the highest score pair and return to the self.merge method.
Remove the # symbols as necessary and merge the highest scoring
pair then return the merged characters to the self.merge method.
Args:
char_1 (str): The first character in the highest-scoring pair.
char_2 (str): The second character in the highest-scoring pair.
Returns:
merged_chars (str): Merged characters.
'''
if char_2.startswith('##'):
merged_chars = char_1 + char_2[2:]
else:
merged_chars = char_1 + char_2
return merged_chars
def initialize_corpus(self, words):
''' Split each word into characters and count the word frequency.
Split each word in the input word list on every character. For each
word, store the split word in a list as the first element inside a
tuple. Store the frequency count of the word as an integer as the
second element of the tuple. Create a tuple for every word in this
fashion and store the tuples in a list called 'corpus', then return
then corpus list.
Args:
None.
Returns:
corpus (list[tuple(list, int)]): A list of tuples where the
first element is a list of a word in the words list (where
the elements are the individual characters of the word),
and the second element is an integer representing the
frequency of the word in the list.
'''
corpus = self.calculate_frequency(words)
corpus = [(self.add_hashes(word), freq) for (word, freq) in corpus]
return corpus
def tokenize(self, text):
''' Take in some text and return a list of tokens for that text.
Args:
text (str): The text to be tokenized.
Returns:
tokens (list): The list of tokens created from the input text.
'''
# Create cleaned vocabulary list without # and commas to check against
clean_vocabulary = [word.replace('#', '').replace(',', '')
for word in self.vocabulary]
clean_vocabulary.sort(key=lambda word: len(word))
clean_vocabulary = clean_vocabulary[::-1]
# Break down the text into the largest tokens first, then smallest
remaining_string = text
tokens = []
keep_checking = True
while keep_checking:
keep_checking = False
for vocab in clean_vocabulary:
if remaining_string.startswith(vocab):
tokens.append(vocab)
remaining_string = remaining_string[len(vocab):]
keep_checking = True
if len(remaining_string) > 0:
tokens.append(remaining_string)
return tokensThe WordPiece algorithm is trained below with the same toy dataset that was given to the BPE algorithm, and this time the tokens that it learns are very different. It is clear to see that WordPiece favours combinations where the characters appear more commonly with each other than without, and so m and p are merged immediately since they only exist in the dataset together and not alone. The idea here is to force the model to consider what is being lost be merging characters together. That is, are these characters always together? In that case the characters should be merged as they are clearly one unit. Alternatively, are the characters very frequent in the corpus anyway? In that case the characters may just be common and so appear next to other tokens by virtue of the abundance in the dataset.
wp = WordPiece()
wp.train(words, 30)
print(f'INITIAL CORPUS:\n{wp.corpus_history[0]}\n')
for rule, corpus in list(zip(wp.merge_rules, wp.corpus_history[1:])):
print(f'NEW MERGE RULE: Combine "{rule[0]}" and "{rule[1]}"')
print(corpus, end='\n\n')INITIAL CORPUS:
[(['c', '##a', '##t'], 5), (['c', '##a', '##t', '##s'], 2),
(['e', '##a', '##t'], 10), (['e', '##a', '##t', '##i', '##n', '##g'], 3),
(['r', '##u', '##n', '##n', '##i', '##n', '##g'], 2),
(['j', '##u', '##m', '##p', '##i', '##n', '##g'], 1),
(['f', '##o', '##o', '##d'], 6)]
NEW MERGE RULE: Combine "##m" and "##p"
[(['c', '##a', '##t'], 5), (['c', '##a', '##t', '##s'], 2),
(['e', '##a', '##t'], 10), (['e', '##a', '##t', '##i', '##n', '##g'], 3),
(['r', '##u', '##n', '##n', '##i', '##n', '##g'], 2),
(['j', '##u', '##mp', '##i', '##n', '##g'], 1),
(['f', '##o', '##o', '##d'], 6)]
NEW MERGE RULE: Combine "r" and "##u"
[(['c', '##a', '##t'], 5), (['c', '##a', '##t', '##s'], 2),
(['e', '##a', '##t'], 10), (['e', '##a', '##t', '##i', '##n', '##g'], 3),
(['ru', '##n', '##n', '##i', '##n', '##g'], 2),
(['j', '##u', '##mp', '##i', '##n', '##g'], 1),
(['f', '##o', '##o', '##d'], 6)]
NEW MERGE RULE: Combine "j" and "##u"
[(['c', '##a', '##t'], 5), (['c', '##a', '##t', '##s'], 2),
(['e', '##a', '##t'], 10), (['e', '##a', '##t', '##i', '##n', '##g'], 3),
(['ru', '##n', '##n', '##i', '##n', '##g'], 2),
(['ju', '##mp', '##i', '##n', '##g'], 1), (['f', '##o', '##o', '##d'], 6)]
NEW MERGE RULE: Combine "ju" and "##mp"
[(['c', '##a', '##t'], 5), (['c', '##a', '##t', '##s'], 2),
(['e', '##a', '##t'], 10), (['e', '##a', '##t', '##i', '##n', '##g'], 3),
(['ru', '##n', '##n', '##i', '##n', '##g'], 2),
(['jump', '##i', '##n', '##g'], 1), (['f', '##o', '##o', '##d'], 6)]
NEW MERGE RULE: Combine "jump" and "##i"
[(['c', '##a', '##t'], 5), (['c', '##a', '##t', '##s'], 2),
(['e', '##a', '##t'], 10), (['e', '##a', '##t', '##i', '##n', '##g'], 3),
(['ru', '##n', '##n', '##i', '##n', '##g'], 2), (['jumpi', '##n', '##g'], 1),
(['f', '##o', '##o', '##d'], 6)]
NEW MERGE RULE: Combine "##i" and "##n"
[(['c', '##a', '##t'], 5), (['c', '##a', '##t', '##s'], 2),
(['e', '##a', '##t'], 10), (['e', '##a', '##t', '##in', '##g'], 3),
(['ru', '##n', '##n', '##in', '##g'], 2), (['jumpi', '##n', '##g'], 1),
(['f', '##o', '##o', '##d'], 6)]
NEW MERGE RULE: Combine "ru" and "##n"
[(['c', '##a', '##t'], 5), (['c', '##a', '##t', '##s'], 2),
(['e', '##a', '##t'], 10), (['e', '##a', '##t', '##in', '##g'], 3),
(['run', '##n', '##in', '##g'], 2), (['jumpi', '##n', '##g'], 1),
(['f', '##o', '##o', '##d'], 6)]
NEW MERGE RULE: Combine "run" and "##n"
[(['c', '##a', '##t'], 5), (['c', '##a', '##t', '##s'], 2),
(['e', '##a', '##t'], 10), (['e', '##a', '##t', '##in', '##g'], 3),
(['runn', '##in', '##g'], 2), (['jumpi', '##n', '##g'], 1),
(['f', '##o', '##o', '##d'], 6)]
NEW MERGE RULE: Combine "jumpi" and "##n"
[(['c', '##a', '##t'], 5), (['c', '##a', '##t', '##s'], 2),
(['e', '##a', '##t'], 10), (['e', '##a', '##t', '##in', '##g'], 3),
(['runn', '##in', '##g'], 2), (['jumpin', '##g'], 1),
(['f', '##o', '##o', '##d'], 6)]
NEW MERGE RULE: Combine "runn" and "##in"
[(['c', '##a', '##t'], 5), (['c', '##a', '##t', '##s'], 2),
(['e', '##a', '##t'], 10), (['e', '##a', '##t', '##in', '##g'], 3),
(['runnin', '##g'], 2), (['jumpin', '##g'], 1),
(['f', '##o', '##o', '##d'], 6)]
NEW MERGE RULE: Combine "##in" and "##g"
[(['c', '##a', '##t'], 5), (['c', '##a', '##t', '##s'], 2),
(['e', '##a', '##t'], 10), (['e', '##a', '##t', '##ing'], 3),
(['runnin', '##g'], 2), (['jumpin', '##g'], 1),
(['f', '##o', '##o', '##d'], 6)]
NEW MERGE RULE: Combine "runnin" and "##g"
[(['c', '##a', '##t'], 5), (['c', '##a', '##t', '##s'], 2),
(['e', '##a', '##t'], 10), (['e', '##a', '##t', '##ing'], 3),
(['running'], 2), (['jumpin', '##g'], 1), (['f', '##o', '##o', '##d'], 6)]
NEW MERGE RULE: Combine "jumpin" and "##g"
[(['c', '##a', '##t'], 5), (['c', '##a', '##t', '##s'], 2),
(['e', '##a', '##t'], 10), (['e', '##a', '##t', '##ing'], 3),
(['running'], 2), (['jumping'], 1), (['f', '##o', '##o', '##d'], 6)]
NEW MERGE RULE: Combine "f" and "##o"
[(['c', '##a', '##t'], 5), (['c', '##a', '##t', '##s'], 2),
(['e', '##a', '##t'], 10), (['e', '##a', '##t', '##ing'], 3),
(['running'], 2), (['jumping'], 1), (['fo', '##o', '##d'], 6)]Now that the WordPiece algorithm has been trained (i.e. now that all have the merging rules have been found), the model can be used to tokenize any text by first splitting each of the words on every character, and then finding the largest token it can at the start of the string, then finding the largest token it can for the remaining part of the string. This process repeats until no more of the strings match a known token from the training data and so the remaining part of the string is taken as the final token.
Despite the limited training data, the model has still managed to learn some useful tokens. But you can quite clearly see that a lot more training data is required to make this tokenizer useful. We can test its performance on some example strings, starting with the word jumper. First the string is broken into ['jump','er'], since jump is the largest token from the training set that can be found at the start of the word. Next, the string er is broken into the individual characters, since the model has not learned to combine the characters e and r.
print(wp.tokenize('jumper'))['jump', 'e', 'r']Unigram
Unigram tokenizers take a different approach to BPE and WordPiece, by starting with a large vocabulary, and iteratively decreasing it until the desired size is reached, instead of the other way around.
The Unigram model uses a statistical approach, where the probability of each word or character in a sentence is considered. For example, in the sentence Cats are great but dogs are better, it can be split into either ['Cats', 'are', 'great', 'but', 'dogs', 'are', 'better'] or ['C', 'a' , 't', 's', '_a', 'r', 'e', '_g','r', 'e', 'a', 't', '_b', 'u', 't', '_d', 'o', 'g', 's' '_a', 'r', 'e', '_b', 'e', 't', 't', 'e', 'r']. Notice how in the case where the sentence is split by characters, an underscore is prepended to the beginning of each character where a space would have been used to mark the start of a new word in the original sentence.
Each element in these lists can be considered a token, t, and the probability of the series of tokens, t1, t2, …, tn, occurring being given by:
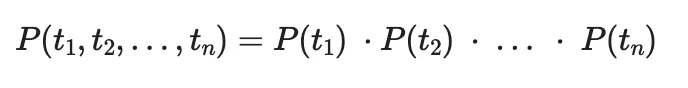
Equation for the probability of a series of tokens
The Unigram model is trained using the following steps:
Step 1) Construct the Corpus
As always, the input text is given to the normalization and pre-tokenization models to create clean words. The words are then given to the Unigram model, which determines the frequency of each word, and stores this number alongside the word in a list called the corpus.
Step 2) Construct the Vocabulary
The vocabulary size of the Unigram model starts out very large, and is iteratively decreased until the desired size is reached. To construct the initial vocabulary, find every possible substring in the corpus. For example, if the first word in the corpus is cats, the substrings ['c', 'a', 't', 's', 'ca', 'at', 'ts', 'cat', 'ats'] will be added to the vocabulary.
Step 3) Calculate the Probability of Each Token
The probability of a token is approximated by finding the number of occurrences of the token in the corpus, and dividing by the total number of token occurrences.

Equation for the probability of a token
Step 4) Find All the Possible Segmentations of the Word
Consider the case where a word from the training corpus is cat. This can be segemented in the following ways:
['c', 'a', 't']
['ca', 't']
['c', 'at']
['cat']
Step 5) Calculate the Approximate Probability of Each Segmentation Occurring in the Corpus
Combining the equations above will give the probability for each series of token. As an example, this might look like:
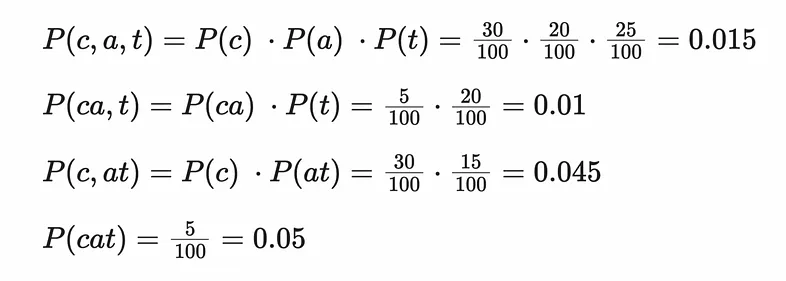
Example equations for calculating the probability the word ‘cat’ occurring in the corpus
Since the segment ['c', 'at'] has the highest probability score, this is the segment that is used to tokenize the word. So the word cat will be tokenized as ['c', 'at']. You can imagine that for longer words such as tokenization, splits may occur in multiple places throughout the word, for example ['token', 'iza', tion] or ['token', 'ization].
Step 6) Calculate the Loss
The term loss refers to a score for the model, such that if an important token is removed from the vocabulary the loss increases greatly, but if a less important token is removed the loss increases greatly. By calculating what the loss would be in the model for each token if it is was removed, it is possible to find the token that is the least useful in the vocabulary. This can be repeated iteratively until the vocabulary size has decreased to only the most useful tokens remain from the training set corpus. The loss is given by:
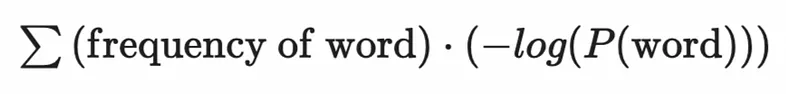
Equation for the loss in the Unigram tokenizer
Once enough characters have been removed to bring the vocabulary down to the desired size, the training is complete and the model can be used to tokenize words.
Comparing BPE, WordPiece, and Unigram
Depending on the training set and the data to be tokenized, some tokenizers may perform better than others. When choosing a tokenizer for a language model, it may be best to experiment with the training set used for a specific use-case and see which gives the best results. However, there are some general tendencies of these three tokenizers that are useful to discuss.
Of the three, BPE seems to be the most popular choice for current language model tokenizers. Although in a such a rapidly changing space, it’s very possible this change in the future. In fact, other subword tokenizers such as SentencePiece have been gaining much more popularity in recent times [13].
WordPiece seems to produce more single-word tokens compared to BPE and Unigram, but irrespective of model choice all tokenizers seem to produce fewer tokens as the vocabulary sizes increases [14].
Ultimately, the choice of tokenizer depends on the datasets that are intended to be used with the model. A safe bet may be to try BPE or SentencePiece, and experiment from there.
Post-Processing
The final step of the tokenization pipeline is post-processing, and is where any final modifications can be made to the output if necessary. BERT famously uses this step to add two additional types of token:
- [CLS] - this token stands for 'classification', and is used to mark beginning of the input text. This is required in BERT, since one of the task it was trained for was classification (hence the name of the token). Even when not being used for classification tasks, this token is still expected by the model.
- [SEP] - this token stands for 'separation' and is used to separate sentences in the input. This is useful for many tasks that BERT performs, including handling multiple instructions at once in the same prompt [15].
Tokenizers in Python Libraries
Hugging Face provides the tokenizers library which is available in several programming languages, including bindings for Python. The library contains a generic Tokenizer class which allows the user to work with pre-trained models, the full list of which can be found on the Hugging Face website [16]. In addition, the library also contains four pre-made but untrained models that the user can train with their own data [17]. These are useful for creating specific tokenizers that are tuned to a particular type of document. The cells below show examples of working with both the pre-trained and untrained tokenizers in Python.
Using a Pre-Trained Tokenizer
The tokenizers library makes it very easy to use a pre-trained tokenizer. Simply import the Tokenizer class, and called the from_pretrained method and pass in the name of the model to use the tokenizer from. A list of models is given in [16].
from tokenizers import Tokenizer
tokenizer = Tokenizer.from_pretrained('bert-base-cased')Training a Tokenizer
To instead use one of the pre-made but untrained tokenizers, simply import the desired model from the tokenizers library, and create an instance of the model class. As stated above, there for four models included in the library:
BertWordPieceTokenizer- The famous Bert tokenizer, using WordPieceCharBPETokenizer- The original BPEByteLevelBPETokenizer- The byte level version of the BPESentencePieceBPETokenizer- A BPE implementation compatible with the one used by SentencePiece
To train the model, use the train method and pass the path to a file (or list of paths to files) containing the training data. Once trained, the model can then be used to tokenize some text using the encode method. Finally, the trained tokenizer can be saved using the save method so that training does not have to be performed again. Below is some example code which has been adapted from the examples available on the Hugging Face Tokenizers GitHub page [17].
# Import a tokenizer
from tokenizers import BertWordPieceTokenizer, CharBPETokenizer, \
ByteLevelBPETokenizer, SentencePieceBPETokenizer
# Instantiate the model
tokenizer = CharBPETokenizer()
# Train the model
tokenizer.train(['./path/to/files/1.txt', './path/to/files/2.txt'])
# Tokenize some text
encoded = tokenizer.encode('I can feel the magic, can you?')
# Save the model
tokenizer.save('./path/to/directory/my-bpe.tokenizer.json')The tokenizer library also provides the components to construct a custom tokenizer very quickly, without having to implement an entire model from scratch as shown in the previous section. The cell below shows an example taken from the Hugging Face GitHub page [17] which shows how to customise the pre-tokenization and decoding stage of the tokenizer. In this case, prefix spaces were added in the pre-tokenization stage, and the decoder chosen was the ByteLevel decoder. A full list of customisation options is available in the Hugging Face documentation [18].
from tokenizers import Tokenizer, models, pre_tokenizers, decoders, trainers, \
processors
# Initialize a tokenizer
tokenizer = Tokenizer(models.BPE())
# Customize pre-tokenization and decoding
tokenizer.pre_tokenizer = pre_tokenizers.ByteLevel(add_prefix_space=True)
tokenizer.decoder = decoders.ByteLevel()
tokenizer.post_processor = processors.ByteLevel(trim_offsets=True)
# And then train
trainer = trainers.BpeTrainer(
vocab_size=20000,
min_frequency=2,
initial_alphabet=pre_tokenizers.ByteLevel.alphabet()
)
tokenizer.train([
"./path/to/dataset/1.txt",
"./path/to/dataset/2.txt",
"./path/to/dataset/3.txt"
], trainer=trainer)
# And Save it
tokenizer.save("byte-level-bpe.tokenizer.json", pretty=True)Conclusion
The tokenization pipeline is a crucial part of any language model, and careful consideration should be given when deciding which type of tokenizer to use. Nowadays, many of these decisions have been made for us by the developers of libraries such as those provided by Hugging Face. These allow users to quickly train and used language models with custom data. However, a solid understanding of tokenization methods is invaluable for fine-tuning models, and squeezing out additional performance on different datasets.
References
[1] Cover Image — Stable Diffusion Web
[2] Token Definition — Stanford NLP Group
[3] Word Tokenizers — Towards Data Science
[4] TransformerXL Paper — ArXiv
[5] Tokenizers — Hugging Face
[6] Word-Based, Subword, and Character-Based Tokenizers — Towards Data Science
[7] The Tokenization Pipeline — Hugging Face
[8] Pre-tokenizers — Hugging Face
[9] Language Models are Unsupervised Multitask Learners — OpenAI
[10] BART Model for Text Autocompletion in NLP — Geeks for Geeks
[11] Byte Pair Encoding — Hugging Face
[12] WordPiece Tokenization — Hugging Face
[13] Two minutes NLP — A Taxonomy of Tokenization Methods — Medium
[14] Subword Tokenizer Comparison — Vinija AI
[15] How BERT Leverage Attention Mechanism and Transformer to Learn Word Contextual Relations — Medium
[16] List of Pre-trained Models — Hugging Face
[17] Hugging Face Tokenizers Library — GitHub
[18] Pre-Tokenization Documentation — Hugging Face
Source: Bradney Smith